

摘要:凤凰网新闻爬虫的设计旨在探索现代网络爬虫在新闻领域的应用与发展。该设计通过技术手段自动抓取凤凰网新闻内容,实现对新闻信息的快速获取和整理。随着网络技术的不断进步,网络爬虫在新闻领域的应用逐渐增多,为新闻报道提供了更高效、准确的信息来源。凤凰网新闻爬虫的设计不仅提高了新闻获取的效率,同时也推动了网络爬虫技术的进一步发展。
本文目录导读:
随着互联网技术的飞速发展,网络爬虫技术在信息获取、数据挖掘等领域扮演着越来越重要的角色,凤凰网作为国内知名的新闻门户网站,其新闻内容的实时更新、丰富多样吸引了大量用户,为了满足用户需求,提高信息获取效率,设计一款针对凤凰网新闻的爬虫显得尤为重要,本文将详细介绍凤凰网新闻爬虫的设计,包括总体设计、关键技术、实现过程等,并探讨其在实际应用中的优势与挑战。
凤凰网新闻爬虫设计的总体架构
1、数据源分析
凤凰网新闻作为我们的数据源,其网页结构、数据更新频率、反爬虫策略等都需要进行详细分析,这有助于我们了解网页结构,确定抓取策略,提高爬虫的稳定性和效率。
2、技术路线选择
根据数据源分析,选择适合的技术路线,如采用Scrapy、PySpider等Python爬虫框架,结合requests、BeautifulSoup等工具进行网页数据抓取和解析。
3、爬虫架构设计
凤凰网新闻爬虫架构包括数据抓取层、数据存储层、业务逻辑层等,数据抓取层负责从网页中获取数据,数据存储层负责将数据存储到本地或数据库中,业务逻辑层则负责处理业务逻辑,如去重、定时任务等。
关键技术实现
1、数据抓取
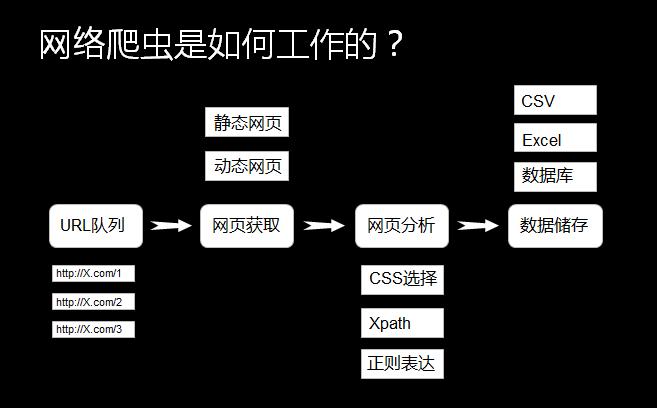
数据抓取是爬虫设计的核心环节,针对凤凰网新闻的网页结构,我们需要利用爬虫框架和工具进行网页请求、页面解析和数据提取,在此过程中,需要解决网页反爬虫策略、动态加载数据获取等问题。
2、数据处理与清洗
抓取到的数据可能包含大量无用信息、重复内容等,需要进行数据处理与清洗,通过正则表达式、自然语言处理等技术,对抓取到的数据进行去重、去噪、格式化等操作,以便后续使用。
3、数据存储
数据存储是保障数据可用性的关键环节,针对凤凰网新闻的特点,我们需要选择合适的数据存储方式,如关系型数据库、非关系型数据库或文件存储等,需要考虑数据的备份、恢复等问题,确保数据的可靠性和安全性。
实现过程与步骤
1、环境搭建与配置
需要搭建适合的开发环境,如Python环境、相关依赖库等,需要配置相应的网络请求代理、防止被封IP等。

2、数据源分析
对凤凰网新闻的网页结构进行详细分析,了解网页中的动态加载数据、反爬虫策略等,为后续的抓取策略制定提供依据。
3、编写爬虫代码
根据技术路线选择和相关技术实现要求,编写爬虫代码,包括数据抓取、数据处理与清洗、数据存储等模块。
4、测试与优化
对编写的爬虫代码进行测试,检查是否存在问题,如抓取不到数据、数据重复等,根据测试结果进行优化,提高爬虫的效率和稳定性。
实际应用中的优势与挑战
1、优势

(1)提高信息获取效率:通过爬虫技术,可以实时获取凤凰网新闻的最新内容,满足用户需求。
(2)丰富数据源:通过爬虫技术,可以获取到大量高质量的新闻内容,为其他业务提供数据支持。
(3)个性化推荐:通过数据分析与挖掘,可以为用户提供个性化的新闻推荐服务。
2、挑战
(1)反爬虫策略:随着网站反爬虫技术的升级,如何突破反爬虫策略成为一大挑战,需要不断关注网站的反爬虫策略变化,及时调整爬虫策略,同时需要遵守相关法律法规和道德准则合法合规地使用爬虫技术获取网站内容避免侵犯版权或其他合法权益。(2)数据质量:如何保证抓取到的数据质量是另一个挑战,需要不断优化数据处理与清洗流程提高数据的准确性和可靠性。(3)数据安全:在数据存储和使用过程中如何保障数据安全也是一个重要问题需要考虑数据的备份恢复加密存储等问题确保数据的安全性和隐私性。(4)技术更新:随着技术的不断发展新的爬虫技术和工具不断涌现需要不断学习新技术保持技术更新以适应不断变化的市场需求和技术环境,同时还需要关注法律法规的变化遵守相关法律法规确保业务的合规性,六总结与展望随着互联网的不断发展网络爬虫技术在信息获取数据挖掘等领域的应用越来越广泛本文详细介绍了凤凰网新闻爬虫的设计包括总体架构设计关键技术实现实现过程与步骤以及实际应用中的优势与挑战通过设计一款针对凤凰网新闻的爬虫可以提高信息获取效率丰富数据源为用户提供个性化的新闻推荐服务但同时也面临着反爬虫策略数据质量数据安全和技术更新等方面的挑战未来随着技术的不断进步和法律法规的完善网络爬虫技术将越来越成熟应用场景也将更加广泛对于凤凰网新闻爬虫的设计也需要不断适应市场需求和技术环境的变化持续优化和改进以提高效率和稳定性为信息获取和数据挖掘领域的发展做出更大的贡献。
 皖ICP备12012634号-14
皖ICP备12012634号-14 皖ICP备12012634号-14
皖ICP备12012634号-14
还没有评论,来说两句吧...